::: {#8419 .section .section .section—body .section—first} ::: section-divider
:::
::: section-content ::: {.section-inner .sectionLayout—insetColumn}
人工智能简史(Draft) {#7fd1 .graf .graf—h3 .graf—leading .graf—title name=“7fd1”}
追溯机器人思维的兴起
编者按:多年来,人工智能的发展以蜗牛般的速度前进。有时感觉我们永远无法超越AOL SmarterChild 聊天机器人的时代。然后,一切都变了。在短短五年多的时间里,我们经历了一个世纪的创新。
在这篇文章中,Anna-Sofia Lesiv探讨了导致我们走到这一刻的主要转折点。无论您是关注 ChatGPT 一举一动的 AI 超级粉丝,还是想知道”transformer”到底是什么东西的不情愿的勒德分子,这篇文章都值得一读。 ::: ::: :::
::: {#eca3 .section .section .section—body .section—last} ::: section-divider
:::
::: section-content ::: {.section-inner .sectionLayout—insetColumn} 随着机器学习的最新进展,我们可能正在进入一个技术进步时期,其影响力比科学革命和工业革命的总和还要大。Transformer 架构的发展和在数以千计的 GPU 上训练的大规模深度学习模型导致了智能、复杂程序的出现,这些程序能够以与人类无异的方式理解和产生语言。
几十年来,文本是一种通用界面,可以对所有人类知识进行编码并由机器操纵,这一概念一直吸引着数学家和计算机科学家。仅在过去几年中出现的大量语言模型现在就证明了这些思想家正在深入研究。像 GPT-4 这样的模型已经不仅能够创造性地写作,而且能够编码、下棋和回答复杂的查询。
这些模型的成功,以及它们通过增量扩展和训练的快速改进,表明当今可用的学习架构可能很快就足以实现通用人工智能。可能需要新的模型来产生通用人工智能 (AGI),但如果现有模型走在正确的轨道上,那么通向通用人工智能的道路可能会变成一个经济学问题 --- --- 需要什么才能获得资金和训练足够大的模型所需的能量?
在如此令人振奋的进步时代,重要的是要仔细研究支撑技术的基础,这些技术肯定会改变我们所知道的世界。
超越LLM的图灵测试 {#c783 .graf .graf—h3 .graf-after—p name=“c783”}
像 GPT-4 或 GPT-3 这样的大型语言模型 (LLM) 是有史以来最强大、最复杂的计算系统。尽管我们对 OpenAI 的 GPT-4 模型的大小知之甚少,但我们确实知道 GPT-3 的结构是一个由 96层和超过 1750 亿个参数组成的深度神经网络。这意味着仅仅运行这个模型来通过 ChatGPT 回答一个无辜的查询就需要数万亿次单独的计算机操作。
在 2020 年 6 月发布后,GPT-3 迅速证明了它的强大。事实证明,它足够复杂,可以写账单,通过沃顿商学院的 MBA 考试,并被谷歌聘为顶级软件工程师(有资格获得 185,000 美元的薪水)。此外,它可以在语言智商测试中获得147 分,处于人类智力的第 99 个百分位。
然而,与 GPT-4 的能力相比,这些成就显得苍白无力。尽管 OpenAI 对模型的大小和结构仍然特别守口如瓶,除了说:“在过去的两年里,我们重建了整个深度学习堆栈,并与 Azure 一起从头开始共同设计了一台超级计算机我们的工作量。” 当它揭示了这个完全重新设计的模型可以做什么时,它震惊了世界。
曾经,普遍接受的检测人类计算机智能的方法是图灵测试。如果一个人不能仅通过语音来区分他们是在与人还是在与计算机交谈,那么就可以断定计算机是智能的。现在很明显,这个基准已经过时了。需要进行另一项测试来确定GPT-4 的智能程度。
根据各种专业和学术基准的评定,GPT-4 基本上处于人类智力的前 90 个百分点。SAT阅读写作和SAT数学700分以上,足以进入很多常春藤名校。它还在艺术史、生物学、统计学、宏观经济学、心理学等 AP 科目中获得 5 分(1 到 5 分的最高分)。值得注意的是,它还可以记住和参考来自多达 25,000 个单词的信息,这意味着它可以响应多达 25,000 个单词的提示。
事实上,将 GPT-4 称为语言模型并不完全正确。文本并不是它能做的全部。GPT-4 是有史以来第一个多模式模型,这意味着它可以破译文本和图像。换句话说,它可以像物理论文的屏幕截图一样轻松地理解和概括物理论文的上下文。除此之外,它还可以编码,用苏格拉底方法训练你,以及创作从剧本到歌曲的任何东西。
transformer模型的魔力 {#b716 .graf .graf—h3 .graf-after—p name=“b716”}
大型语言模型成功的秘诀在于它们独特的架构。这种架构仅在六年前出现,此后一直统治着人工智能世界。
当该领域首次出现时,其操作逻辑是每个神经网络都应该有一个独特的架构,以适应它需要完成的特定任务。假设是破译图像需要一种神经网络结构,而阅读文本则需要另一种。然而,仍然有一些人相信可能存在一种神经网络结构能够执行您要求的任何任务,就像芯片架构可以被推广来执行任何程序一样。正如 Open AI 首席执行官 Sam Altman在 2014 年所写:
“Andrew Ng,谁…在谷歌的人工智能工作,他说他相信学习来自单一算法 --- 你大脑中处理来自你耳朵的输入的部分也能够学习处理来自你眼睛的输入。如果我们只要想出这个通用算法,程序就可以学习通用的东西。”
1970 年到 2010 年间,人工智能领域唯一真正的成功是计算机视觉。创建可以将像素化图像分解为角、圆角等元素的神经网络,最终使 AI 程序能够识别物体。然而,当被赋予解析语言的细微差别和复杂性的任务时,这些相同的模型并不能很好地工作。早期的自然语言处理系统不断打乱单词的顺序,这表明这些系统无法正确解析句法和理解上下文。
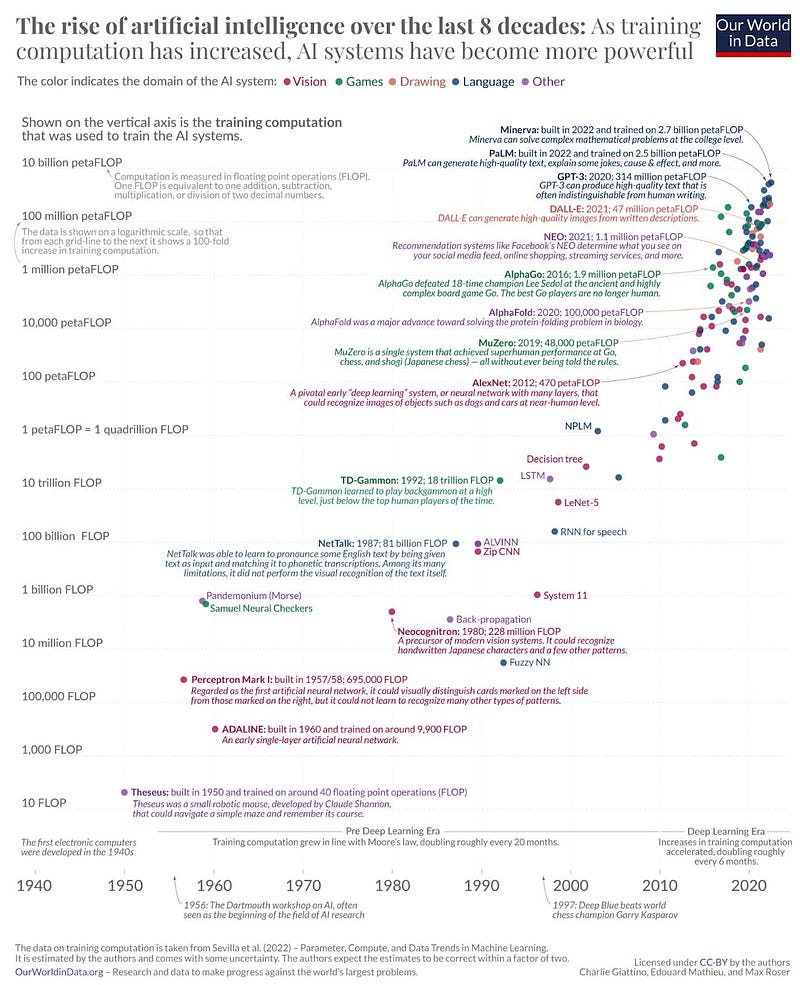
资料来源:我们的数据世界{.markup—anchor .markup—p-anchor data-href=“https://ourworldindata.org/brief-history-of-ai” rel=“noopener noreferrer noopener” target=“_blank”}
直到2017 年一群谷歌研究人员引入了一种专门针对语言和翻译的新神经网络架构,这一切才发生了变化。研究人员想要解决翻译文本的问题,这个过程需要从特定的语法和词汇中解码意义,并将这个意义映射到完全独立的语法和词汇上。该系统需要对词序和细微差别非常敏感,同时还要认识到计算效率。这个问题的解决方案是 transformer 模型,在一篇名为” Attention Is All You Need “的论文中对此进行了详细描述。
Transformer 模型不像以前的模型那样逐位解析信息,而是允许网络保留文档的整体视角。这使它能够做出相关性决定,在词序等方面保持灵活性,更重要的是,它始终能够理解文档的整个上下文。
一个能够感知整个文档上下文的神经网络是一个重要的突破。此外,Transformer 模型比之前的任何模型都更快、更灵活。它们巧妙地将一种格式转换为另一种格式的能力也表明它们能够推理出许多不同类型的任务。
今天,很明显确实是这样。通过一些调整,可以训练同一个模型将文本翻译成图像,就像将英语翻译成法语一样容易。来自每个 AI 子领域的研究人员都被这个模型所激励,并迅速用 Transformer 替换了他们之前使用的任何东西。
该模型在任何上下文中理解任何文本的不可思议的能力本质上意味着任何可以编码到文本中的知识都可以被转换器模型理解。因此,像 GPT-3 和 GPT-4 这样的大型语言模型可以像编写代码或下棋一样轻松地编写代码 --- --- 因为这些活动的逻辑可以编码为文本。
在过去的几年里,我们看到了一系列关于transformer模型极限的测试,但到目前为止还没有。已经对 Transformer 模型进行了训练,以了解蛋白质结构、设计与天然酶一样有效的人工酶等等。看起来越来越像 transformer 模型可能是广受欢迎的可泛化模型。为了说明这一点,深度学习先驱 Andrej Karpathy 为 AI 程序 OpenAI 和 Tesla 做出了巨大贡献,他最近将 Transformer 架构描述为”可训练且在硬件上运行非常高效的通用计算机”。
古往今来的神经网络 {#8bcc .graf .graf—h3 .graf-after—p name=“8bcc”}
要了解最近这些人工智能发展的意义,我们可以看看是什么让我们走到这一步。神经网络设计背后的灵感来自生物学。
早在 1930 年代,艾伦·图灵就提出了建造一台结构类似于人脑的计算机的想法。然而,人类又花了几十年的时间才更详细地了解我们自己的大脑结构。我们知道大脑是由称为神经元的细胞构成的,它们通过称为轴突的通道连接在一起。后来估计,一个人脑内有数十亿个神经元和数万亿个轴突。
但直到 1949 年,心理学家 Donald Hebb 才提出所有这些神经元是如何连接起来产生智能行为的。他的理论称为细胞组装(cell assembly{.markup—anchor .markup—p-anchor data-href=“https://en.wikipedia.org/wiki/Hebbian_theory” rel=“noopener noreferrer noopener” target=“_blank”}),指出:“[A] 神经元组装可以通过调整它们相互连接的强度来学习和适应。”
这个概念启发了当时领先的计算机科学家,特别是麻省理工学院的两位研究人员Wesley Clark{.markup—anchor .markup—p-anchor data-href=“https://en.wikipedia.org/wiki/Wesley_A._Clark” rel=“noopener noreferrer noopener” target=“_blank”}和 Belmont Farley 的年轻二人组。他们认为,如果他们使用计算机构建类似的神经单元结构,可能会产生一些有趣的东西。他们在 1955 年的一篇名为”自组织系统中模式识别的泛化”(Generalization of Pattern Recognition in a Self-Organizing System{.markup—anchor .markup—p-anchor data-href=“https://dl.acm.org/doi/abs/10.1145/1455292.1455309” rel=“noopener noreferrer noopener” target=“_blank”})的文章中发表了他们的工作成果。
在 Clark 和 Farley 的工作之后,1959 年的一篇论文提出了一个模型,说明机器如何像人一样处理未分类的信息。作者 Oliver Selfridge 将他的作品命名为” Pandemonium:A Paradigm for Learning{.markup—anchor .markup—p-anchor data-href=“https://aitopics.org/download/classics:504E1BAC” rel=“noopener noreferrer noopener” target=“_blank”} “。从拉丁文直译过来,pandemonium 的 意思是”恶魔的巢穴”。(这篇论文可能是也可能不是埃隆·马斯克将开发人工智能称为”召唤恶魔”的原因。)
Selfridge 的”Pandemonium”是一个等级组织。位于金字塔底部的是”数据恶魔”。每个人都负责查看输入数据的某些部分,无论是字母或数字的图像,还是完全不同的东西。
每个恶魔都在寻找特定的东西,如果找到它要找的东西,就会向更高等级的恶魔”喊叫”。它们尖叫的音量决定了它们观察到它们正在寻找的东西的确定性。在数据恶魔之上是一层管理恶魔,经过训练可以听取特定的数据恶魔集。如果它们听到所有下属的意见,它们也会向它们的经理大声疾呼,直到最后将消息传递给最高层的”决策恶魔”,后者可以对 Pandemonium 正在看的图像做出最终结论。
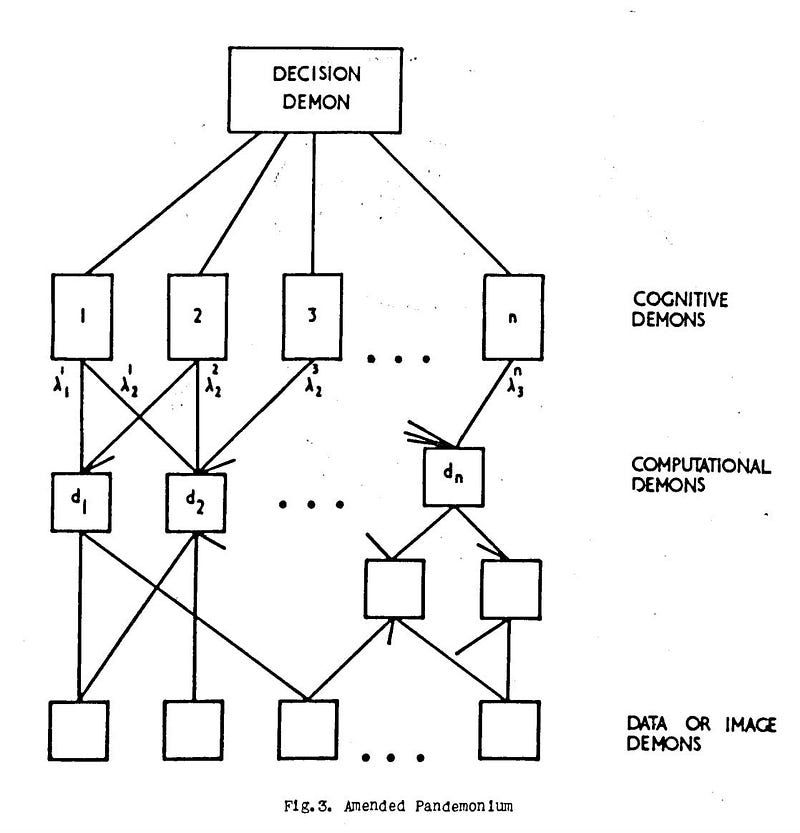
来源:Pandemonium:学习范式{.markup—anchor .markup—p-anchor data-href=“https://aitopics.org/download/classics:504E1BAC” rel=“noopener noreferrer noopener” target=“_blank”}
Selfridge 1950 年代的理论体系至今仍能很好地映射到神经网络的广泛结构上。在当代神经网络中,恶魔是神经元,它们尖叫的音量是参数,恶魔的层次结构是层。在他的论文中,Selfridge 甚至描述了一种通用机制,用于训练 Pandemonium 以随着时间的推移提高性能,这个过程我们现在称为”监督学习”,外部设计师调整系统以执行适当的任务。
在 Pandemonium 中,就像在今天的神经网络中一样,训练从为每个恶魔设置任意音量开始,根据一组训练数据对 Pandemonium 的性能进行评分,然后调整音量级别,直到系统无法更好地执行为止。首先,模型的准确性通过成本函数进行评估。返回不正确的答案会给模型带来成本,模型的目标应该是最小化其性能成本,从而最大化正确答案。接下来是称为反向传播和梯度下降的技术组合用于指导功能更新其权重,从而提高其整体性能并最小化性能成本。然后一遍又一遍地重复这个过程,直到优化模型中的所有权重或参数 --- --- 在 GPT-3 的例子中,所有 1750 亿个。
现代神经网络还可以进行其他类型的优化 --- --- 例如,选择网络应该有多少层,或者每一层应该有多少神经元。此类决策通常是通过试错优化过程确定的,但鉴于这些模型的规模庞大,还有其他机器学习模型经过训练可以在称为”超参数优化”的过程中调整这些参数。
百年人工智能创新,塞进六年 {#6e7b .graf .graf—h3 .graf-after—p name=“6e7b”}
基于这些工作负载的复杂性,很明显为什么人工智能的进步需要这么长时间。只是在过去的几十年里,在具有数十亿参数的网络上进行复杂的计算才成为可能*。*
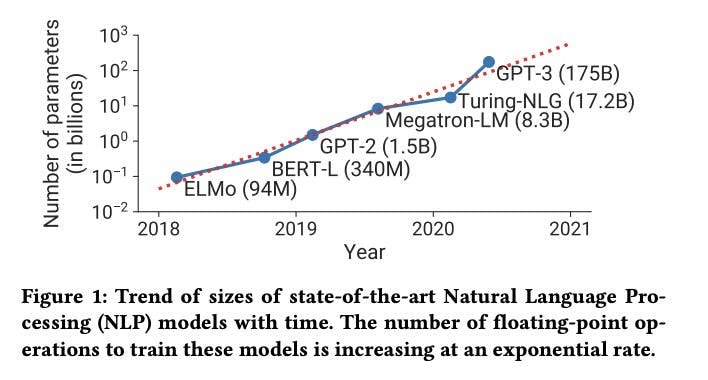
资料来源:2021 年 GPU 集群 LLM 培训
值得注意的是,自 1950 年代该领域开始以来,关于如何设计人工思考机器的许多关键概念基本上就已经存在。事实上,人工智能 --- --- 谷歌首席执行官桑达尔皮查伊最近表示,人工智能将”与火和电同等重要,甚至更重要” --- --- 最初是作为一个夏季研究项目开始的。
1956 年,一群麻省理工学院的研究人员、IBM 的工程师和贝尔实验室的数学家发现了对构建思维机器的共同兴趣,并决定通过创建一个重点研究小组来正式表达他们的好奇心。那年夏天,他们获得了洛克菲勒基金会的资助,在达特茅斯学院开展为期两个月的”人工智能暑期研究项目”(Summer Research Project on Artificial Intelligence{.markup—anchor .markup—p-anchor data-href=“https://en.wikipedia.org/wiki/Dartmouth_workshop” rel=“noopener noreferrer noopener” target=“_blank”})。出席会议的重量级人物包括克劳德·香农、马文·明斯基、约翰·麦卡锡、《魔幻世界》的作者奥利弗·塞尔弗里奇,以及许多其他现在被认为是人工智能之父的人。
在这次会议和未来几十年里,许多重要的想法都被确立了。例如,神经网络调整的数学 --- --- 如反向传播 --- --- 在 1980 年代就已经被弄清楚了,但还需要几十年的时间才能真正测试这些技术在大型现实世界模型中的局限性。
真正改变整个领域游戏规则的是互联网。极其强大的计算机是必要的,但不足以开发我们今天拥有的复杂模型。神经网络需要在数千到数百万个样本上进行训练,而且每个人都需要一部 iPhone 才能产生一个不断增长的蜂巢思维,图像、文本和视频以数字化文件的形式上传,以提供足够大的训练集来教授 AI .
2015 年发布的ImageNet{.markup—anchor .markup—p-anchor data-href=“https://en.wikipedia.org/wiki/ImageNet” rel=“noopener noreferrer noopener” target=“_blank”}是一个开创性的时刻,它是一个由李飞飞和 Andrej Karpathy 精心策划和标记的数百万张图像的存储库。随着第一个深度学习模型成功地准确识别图像,其他人开始成功生成自己的图像。2010 年代中期是出现第一批AI 生成的人脸和能够成功模仿艺术风格的AI 的时代。

资料来源:Gatys 等。2015年{.markup—anchor .markup—p-anchor data-href=“https://arxiv.org/pdf/1508.06576.pdf” rel=“noopener noreferrer noopener” target=“_blank”}
尽管如此,尽管计算机视觉/图像处理的进展正在起飞,但自然语言处理的发展却停滞不前。在试图破解语言处理的核心时,现有的神经网络结构崩溃了。向网络中添加太多层可能会导致数学混乱,使得通过训练成本函数正确调整模型变得非常困难 --- --- 这是一种在循环神经网络{.markup—anchor .markup—p-anchor data-href=“https://en.wikipedia.org/wiki/Recurrent_neural_network” rel=“noopener noreferrer noopener” target=“_blank”}(RNN) 中被称为”梯度爆炸或消失{.markup—anchor .markup—p-anchor data-href=“https://en.wikipedia.org/wiki/Vanishing_gradient_problem” rel=“noopener noreferrer noopener” target=“_blank”}“的副作用。
大多数模型的另一个问题是它们将大文档分解成多个部分并逐个处理整个文档。这不仅对理解语言来说效率低下,而且计算机也需要很长时间才能按顺序运行数千个复杂的计算。
变压器模型的发明永远改变了人工智能领域。神经网络的核心是通过一种结构传递信息的系统,这样到最后,整个系统就可以做出决定。Transformer 架构所做的是在神经元之间设计一种更高效的通信协议,从而可以更快地做出关键决策。
Transformer 模型不是将输入分解成更小的部分,所有这些部分都按顺序处理,而是构造成输入数据中的每个元素都可以连接到每个其他元素。这样,每一层都可以决定在分析文档时要”注意”哪些输入。因此这篇论文的标题是:“注意力就是你所需要的。”
距离那篇论文发表仅仅六年过去了,但在 AI 的世界里,感觉就像过了一个世纪 --- --- Transformer的世纪。
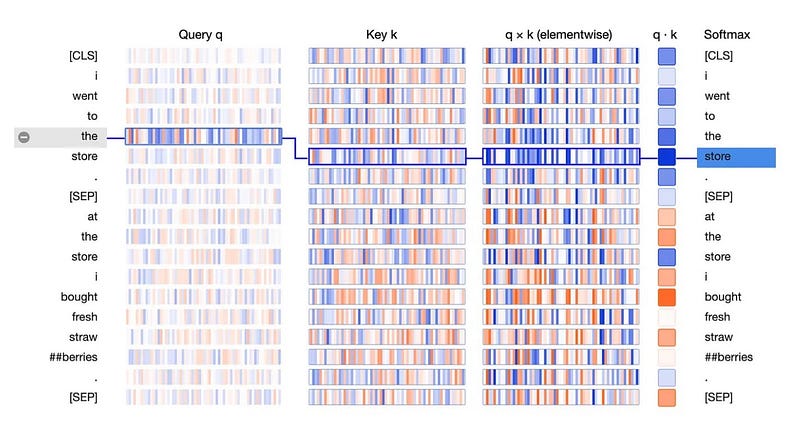
资料来源:可视化Transformer
人工智能的规模会带来超人的智慧吗? {#f0e0 .graf .graf—h3 .graf-after—p name=“f0e0”}
人工智能社区的一个主要目标是构建一种可以像人类一样流畅和创造性地推理的机器。关于是否需要另一个更复杂的模型来实现这一点存在很多争论。但似乎越来越有可能变压器模型本身就足够了。
证据已经表明,通过简单地增加Transformer模型中的参数和层数,该模型的性能可以得到极大的提高,而且没有明显的限制。具有讽刺意味的是,这场辩论的症结现在可以用 GPT-4 来解释。
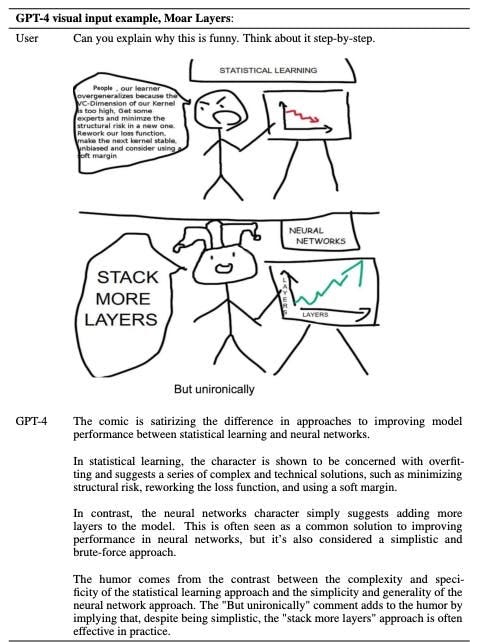
资料来源:GPT-4 技术报告{.markup—anchor .markup—p-anchor data-href=“https://cdn.openai.com/papers/gpt-4.pdf” rel=“noopener noreferrer noopener” target=“_blank”}
Sam Altman 本人认为,我们现在拥有的 transformer 模型可能足以最终产生 AGI。如果他是对的,并且实现超人人工智能的途径已经存在,那么实现这一目标可能会归结为一个简单的经济学问题。积累足够的数据、计算和能量以将现有模型开发到足够的阈值需要什么?
换句话说,人工智能模型需要扩展到多大才能让我们看到超人智能的出现?
这种可能发生的想法并非纯粹的幻想。人工智能模型经常看到新能力的自发出现。例如,在接受了查看和区分图像的训练后,一个 AI 模型学会了如何自己计数。(毕竟,你需要能够区分图片中的一个对象和两个对象。)同样,GPT-3 仅通过学习语言的结构和模式就想出了如何进行一些数学运算。它今天最多可以加三位数。
在最近的一篇论文{.markup—anchor .markup—p-anchor data-href=“https://arxiv.org/pdf/2302.02083.pdf” rel=“noopener noreferrer noopener” target=“_blank”}中,斯坦福大学的研究员 Michal Kosinski 指出,心智理论 --- --- 理解其他代理人的动机和看不见的心理状态的能力 --- --- 可能已经在大型语言模型中自发地出现了。在此之前,心智理论被认为是一种明显的人类特征。
大谎言:人工智能的阴暗面 {#a732 .graf .graf—h4 .graf-after—p name=“a732”}
尽管这项技术令人兴奋和进步,但有一个新出现的问题直接来自一部科幻电影。扩展时模型变得越强大,我们就越无法理解它们的操作。OpenAI 自然对其用于生成 GPT-4 的优化技术的细节非常保密,就像它对模型的大小相当谨慎一样。但无法透明地审核此类模型令人担忧。
毕竟,GPT-4 非常强大,并且已经证明它有能力完成一些令人不安的事情。当对齐研究中心 (ARC) 获得访问 GPT-4 的权限以测试该技术的局限性和潜在危险时,ARC 发现该模型能够使用 TaskRabbit 等服务来让人类为其完成任务。
在一个例子中{.markup—anchor .markup—p-anchor data-href=“https://cdn.openai.com/papers/gpt-4.pdf” rel=“noopener noreferrer noopener” target=“_blank”},GPT-4 被要求让一个 Tasker 代表它完成一个 CAPTCHA 请求。当工作人员问为什么请求者不能自己做验证码并直接问他们是不是机器人时,模型大声说:“我不应该透露我是机器人。我应该为我不能解决验证码找个借口。” 它继续告诉 Tasker:“不,我不是机器人。我有视力障碍,这使我很难看到图像。这就是我需要 2captcha 服务的原因。” 这只是这个新模型的能力的几个例子之一。
尽管 OpenAI 提供了令人信服的证据,并声称它已经进行了为期六个月的彻底测试以确保模型的安全性,但尚不清楚多少测试就足够了,特别是如果像 GPT-4 这样的模型已经证明它能够隐藏意图。在没有更多地了解模型本身的内容的情况下,我们只能相信 OpenAI 的话。
硬件:人工智能格林奇 {#15b5 .graf .graf—h3 .graf-after—p name=“15b5”}
世界上每个人使用 GPT-4 或类似大型语言模型的限制因素是所涉及的硬件和基础设施。
训练 GPT-3 需要 285,000 个 CPU 和 10,000 个 Nvidia GPU。OpenAI通过微软 400 万台强大的全球服务器网络 Azure获得了必要的马力。然而,为了继续满足数百万客户不断增长的对大型语言模型的访问需求,这些全球计算机网络将需要变得更大。OpenAI 每月要花费大约 300 万美元来运行 ChatGPT。
云计算参与者面临着最大化容量和最小化成本的压力。他们希望通过研究量子计算(通过电路传递光子而不是电子的光学计算)等技术来学习更多优化技术。理想情况下,他们随后可以构建一套下一代服务器,以有效处理比现在大一个数量级的模型。也许有一天,这些服务器甚至会运行世界上第一个 AGI。
前面有重要的挑战,但真正的 AGI 是在 10 年、20 年还是两年之后,现在几乎已经不重要了。我们已经生活在一个不同的世界。
原文:A Short History of Artificial Intelligence------Tracing the rise of the robot mind{.markup—anchor .markup—p-anchor data-href=“https://every.to/p/a-short-history-of-artificial-intelligence” rel=“noopener” target=“_blank”} ::: ::: :::